Arquitectura P2P: como funciona la red entre iguales


La arquitectura Peer-to-Peer (P2P), o “red entre iguales”, es un modelo de comunicación en el que todos los dispositivos conectados funcionan al mismo tiempo como cliente y servidor. Es decir, cada computadora puede consumir recursos de otros nodos y, a la vez, ofrecer recursos propios.
Este modelo rompe con la tradicional arquitectura Cliente-Servidor, en la que todo depende de un servidor central. Mientras que en Cliente-Servidor el servidor concentra los datos, la seguridad y la lógica de negocio, en P2P el objetivo es la descentralización.
Esto se traduce en:
👉 En Cliente-Servidor, si el servidor falla, todo el sistema cae.
👉 En P2P, cuantos más nodos se conectan, más fuerte y escalable se vuelve la red.
Cómo se estructura una red P2P
Aunque la idea principal del P2P es la descentralización, no todas las redes funcionan igual. Según el grado de centralización, podemos encontrar tres tipos principales de arquitecturas:
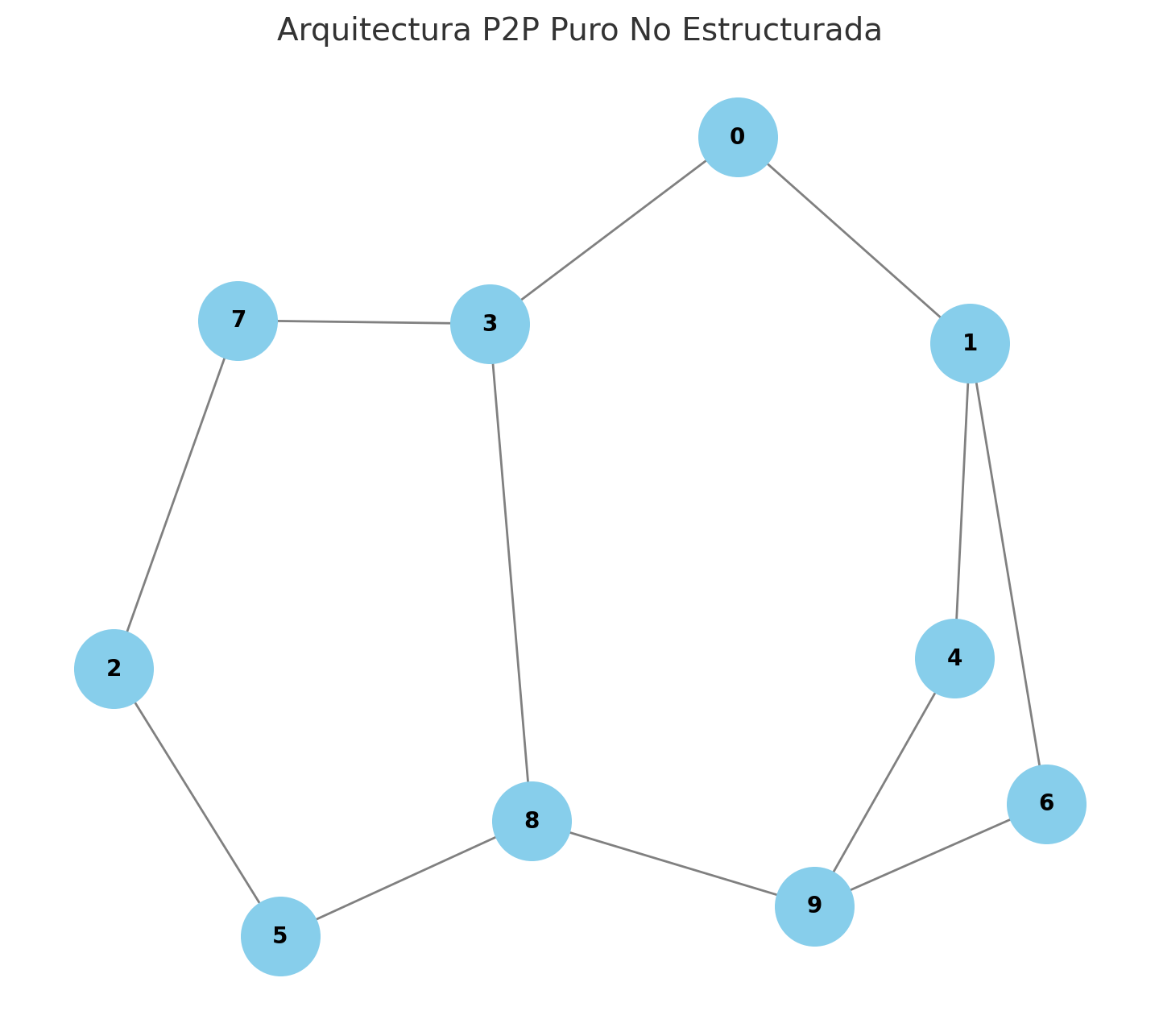
P2P puro no estructurado
Imagina que todos los nodos son iguales, sin jerarquías.
- No existe un servidor central.
- Cada nodo conoce únicamente a un grupo reducido de “vecinos”.
- Para buscar un archivo se usa un algoritmo de inundación: un nodo pregunta a sus vecinos, esos vecinos preguntan a los suyos, y así sucesivamente.
👉 Ventaja: es muy difícil de detener y ofrece bastante privacidad.
👉 Desventaja: genera muchísimo tráfico en la red y no escala bien cuando hay muchos usuarios.
Ejemplos reales: Gnutella, FreeNet.
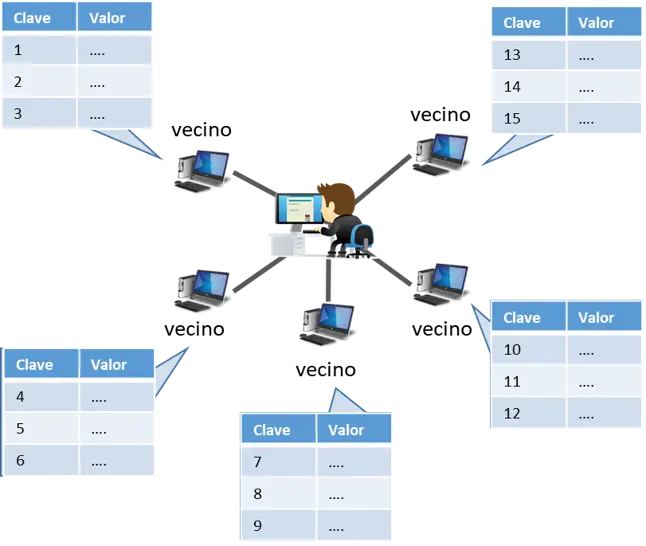
P2P puro estructurado
Aquí el sistema es más ordenado porque usa Tablas Hash Distribuidas (DHT).
- Una DHT funciona como un gran índice repartido entre todos los nodos.
- Cada nodo es responsable de administrar una parte de ese índice global.
- Así, cuando buscas un recurso, no necesitas inundar la red, solo ir directo al nodo que lo tiene.
👉 Ventaja: permite localizar un archivo incluso si solo hay una copia en toda la red.
👉 Desventaja: mantener la tabla actualizada es complicado, porque los usuarios suelen entrar y salir de la red constantemente.
Ejemplos reales: Chord, Kademlia, Pastry, Tapestry.
P2P híbrido
En este caso sí existe un servidor central, pero con un rol diferente:
- El servidor no almacena los archivos.
- Su función es llevar un registro de qué nodo tiene qué recurso.
- Cuando quieres un archivo, el servidor te dice dónde encontrarlo y luego descargas directamente del nodo que lo posee.

👉 Ventaja: las búsquedas son rápidas y fáciles para el usuario.
👉 Desventaja: si el servidor central falla, toda la red deja de funcionar (único punto de fallo).
Ejemplos reales: Napster, eDonkey, BitTorrent, Skype.
¿Cuándo utilizar una arquitectura P2P?
La arquitectura P2P (Peer-to-Peer) no se usa en todos los proyectos. Es muy potente, pero también tiene limitaciones. Para entender cuándo conviene aplicarla, piensa en situaciones donde necesitas que muchos usuarios colaboren entre sí sin depender de un servidor central.
Algunos casos típicos son:
Compartir archivos
Ejemplo clásico: BitTorrent.
Si quieres que los usuarios puedan intercambiar música, videos, documentos u otros archivos sin necesidad de un servidor que los guarde todos, el P2P es ideal.
👉 Entre más usuarios haya, más rápido y eficiente será el intercambio.
Transmisión de contenido en vivo (streaming)
Ejemplo: P2PTV o programas como SopCast.
Cuando un servidor transmite un video en vivo a miles de personas, puede saturarse. Con P2P, cada espectador no solo recibe la señal, sino que también la comparte con otros, reduciendo la carga en el servidor principal.
Procesamiento distribuido
Ejemplo: SETI@home o BOINC.
Si un problema necesita muchísima potencia de cálculo (como analizar señales del espacio o estudiar datos médicos), se puede dividir en pequeñas partes y repartirlas entre miles de computadoras de usuarios voluntarios.
Criptomonedas y blockchain
Ejemplo: Bitcoin o Ethereum.
Las transacciones no pasan por un banco, sino que todos los nodos de la red verifican que sean válidas. Así se evita depender de una sola entidad y se gana seguridad y descentralización.
Aplicaciones descentralizadas (dApps)
Cuando no quieres que exista un único dueño de la aplicación (como puede pasar con redes sociales o mensajerías tradicionales), el P2P permite crear sistemas resistentes a la censura y difíciles de detener.
Usa P2P cuando tu aplicación necesita escalar fácilmente, compartir recursos entre muchos usuarios o evitar depender de un servidor central.
No es recomendable si buscas algo simple, con pocos usuarios o donde la seguridad y el control centralizado sean más importantes.
Creando tu primera app P2P en Python (puro no estructurado)
Vamos a construir un ejemplo muy sencillo de red P2P no estructurada. La idea es que cada nodo de la red sea capaz de:
- Escuchar conexiones de otros nodos (actuar como servidor).
- Conectarse a otros nodos (actuar como cliente).
- Compartir y buscar mensajes entre sus “vecinos” usando un sistema parecido al de la inundación.
De esta forma, podrás ver cómo funciona la comunicación entre iguales sin depender de un servidor central.
De este modo conseguiremos que:
- Cada nodo funcione como cliente y como servidor al mismo tiempo.
- La comunicación se haga entre vecinos directos.
- El mensaje se inunde por la red, igual que en un P2P puro no estructurado.
Paso 1: Preparar el entorno
Necesitas tener instalado Python 3 en tu computadora.
Puedes comprobarlo con:
Paso 2: Crear el archivo node.py
Este será el programa que representará a un nodo P2P.
Paso 3: Probar la red
Abre tres terminales diferentes.
Ejecuta el programa en cada terminal con un puerto distinto:
👉 Ejemplo: uno en el puerto 5000, otro en el 5001 y otro en el 5002.
Edita la lista neighbors dentro de cada archivo node.py para que conozcan al menos a un vecino.
Por ejemplo, en el nodo 5000:
En el nodo 5001:
En el nodo 5002:
Ahora escribe un mensaje en cualquiera de los nodos:
👉 Verás cómo ese mensaje se propaga a través de los vecinos hasta llegar a todos los nodos conectados.
P2P híbrido en Python (simulando un servicio tipo torrent)
Para entender mejor cómo funciona la arquitectura P2P híbrida, vamos a simular un sistema parecido a los torrents. La idea es usar conceptos que ya conoces: un servidor central (que será el tracker) y varios clientes (los peers). El tracker no guarda los archivos, solo mantiene una lista de qué peer tiene qué piezas. Los peers, en cambio, se conectan entre ellos directamente para intercambiar las piezas y reconstruir el archivo completo. De esta forma, podrás ver cómo se combinan los roles de cliente-servidor con la descentralización propia del P2P, pero usando mecanismos sencillos en Python.
En un P2P híbrido hay dos actores:
Tracker (servidor central):
- Mantiene un índice: qué peers tienen qué archivo/piezas.
- Responde a:
announce: “yo, peer X, tengo estas piezas del archivo F”.peers: “dame la lista de peers que tienen el archivo F”.
Peers (nodos):
- Anuncian al tracker lo que tienen.
- Piden al tracker una lista de peers para un archivo.
- Se conectan directamente entre ellos para intercambiar piezas.
Nota: Usamos solo librerías estándar (sin
requests). El tracker va conhttp.servery los peers usanurllibpara consultarlo + sockets para intercambiar piezas.
1) tracker.py — Servidor de coordinación
Guarda esto como tracker.py:
Qué hace:
GET /announce: registra que un peer tiene ciertas piezas de unfile_id.GET /peers: devuelve la lista de peers (y opcionalmente qué piezas tiene cada uno).
2) peer.py — Nodo que sube/baja piezas
Este peer:
- Levanta un servidor TCP sencillo para servir piezas.
- Se anuncia al tracker con las piezas que tiene.
- Pregunta al tracker por peers que tengan el archivo y descarga piezas que le falten.
Guarda esto como peer.py:
Qué hace:
- Si el peer tiene un archivo local, lo parte en piezas y lo comparte.
- Si no lo tiene, se anuncia al tracker con lo que tiene (nada) y descarga las piezas desde otros peers que sí las tengan.
- El tracker nunca ve los datos, solo quién tiene qué.
3) Cómo probarlo en local
Lanza el tracker en una terminal:
Peer seeder (el que ya tiene el archivo):
- Prepara un archivo de prueba, por ejemplo:
archivo_demo.bin(puede ser cualquier fichero). - Lanza un peer que lo comparta, por ejemplo en el puerto 5000:
Peer leecher (descargador):
- Lanza uno o más peers sin archivo, por ejemplo 5001 y 5002:
Verás cómo:
- Los peers se anuncian al tracker.
- Los leechers piden lista de peers y van solicitando piezas por TCP.
- Cuando completan todas las piezas, reconstruyen el archivo en disco (si diste una ruta).
Topología general
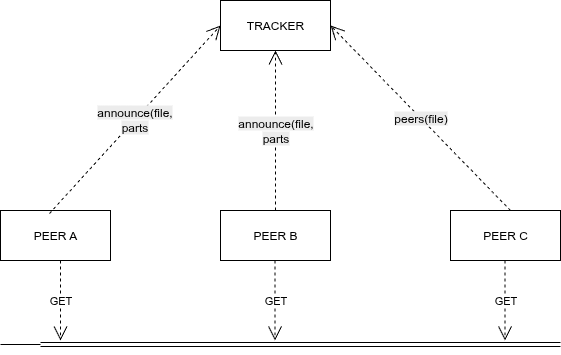
Lectura rápida:
- Los peers se anuncian al tracker con qué piezas tienen.
- Cuando un peer quiere descargar un archivo, pide al tracker una lista de peers para ese
file_id. - La transferencia real de piezas ocurre directamente entre peers por TCP (el tracker no toca datos).
Flujo de mensajes (secuencia)
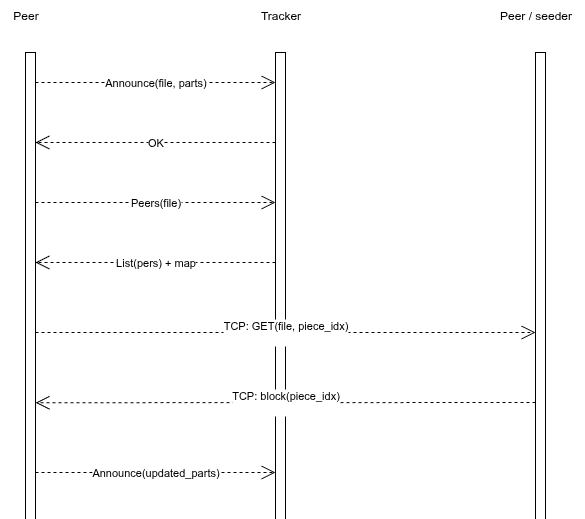
Qué muestra:
- Announce: el peer informa al tracker qué piezas tiene (o ninguna si empieza de cero).
- Peers: el peer solicita al tracker la lista de candidatos para ese archivo.
- Transferencia: el peer pide piezas específicas por TCP a otros peers.
- Reanuncio: al obtener nuevas piezas, vuelve a anunciarse para que otros sepan que ahora también puede compartirlas.
Leyenda rápida
- Tracker: índice central (no almacena archivos), único punto de fallo del modelo híbrido.
- Peers: pares simétricos; suben y bajan piezas.
- ANNOUNCE/PEERS (HTTP): control y coordinación.
- GET pieza (TCP): transferencia de datos real, P2P puro entre nodos.
Si quieres, puedo añadir hash por pieza, rarest-first y paralelismo en otro diagrama para acercarlo aún más a un cliente torrent real.
Qué has aprendido (y siguientes mejoras)
- El tracker solo coordina (índice de piezas/peers) ⇒ no transfiere datos.
- Los peers hacen el intercambio directo punto a punto.
- Simulas el flujo básico de un torrent (announce, peers, piezas).
Mejoras que puedes implementar:
- TTL / IDs de mensajes y caché para evitar duplicados en otros escenarios.
- Rarest-first: priorizar piezas más escasas según
pieces_map. - Verificación por hash por pieza (integridad).
- Intercambio simultáneo (pedir distintas piezas a distintos peers en paralelo).
- Reanudar descargas (persistir mapa de piezas en disco).
- NAT traversal (más avanzado: UDP hole punching).
Si quieres, te preparo una versión con verificación de integridad por hash y descarga en paralelo para que veas cómo se acercaría más a un cliente torrent real.
